As I’m sure anyone who has begun exploring the GDELT data has noticed, there
are a large number of unique actors coded in the data. While working on a
project for a colleague, I began to wonder exactly how many unique actor
codes exist in the dataset, and what the maximum level of actor code complexity
is within the dataset. For those who don’t know, the actor codes are created
by chaining together three character CAMEO actor codes, which results in actor
codes that look like USAMIL, which indicates the United States military. The complexity
of the actor code, then, refers to how many of these three character codes are
chained together.
Results
Using the Python code available here, I iterated over the dataset and identified each unique actor code in the data, along with how many times the unique code appeared. The resulting data is available here. The results indicate that there are 22,857 unique actors in the dataset, with a maximum of 6 three character codes chained together. The following two plots show the top twenty actor codes overall, along with the top twenty USA actor codes.
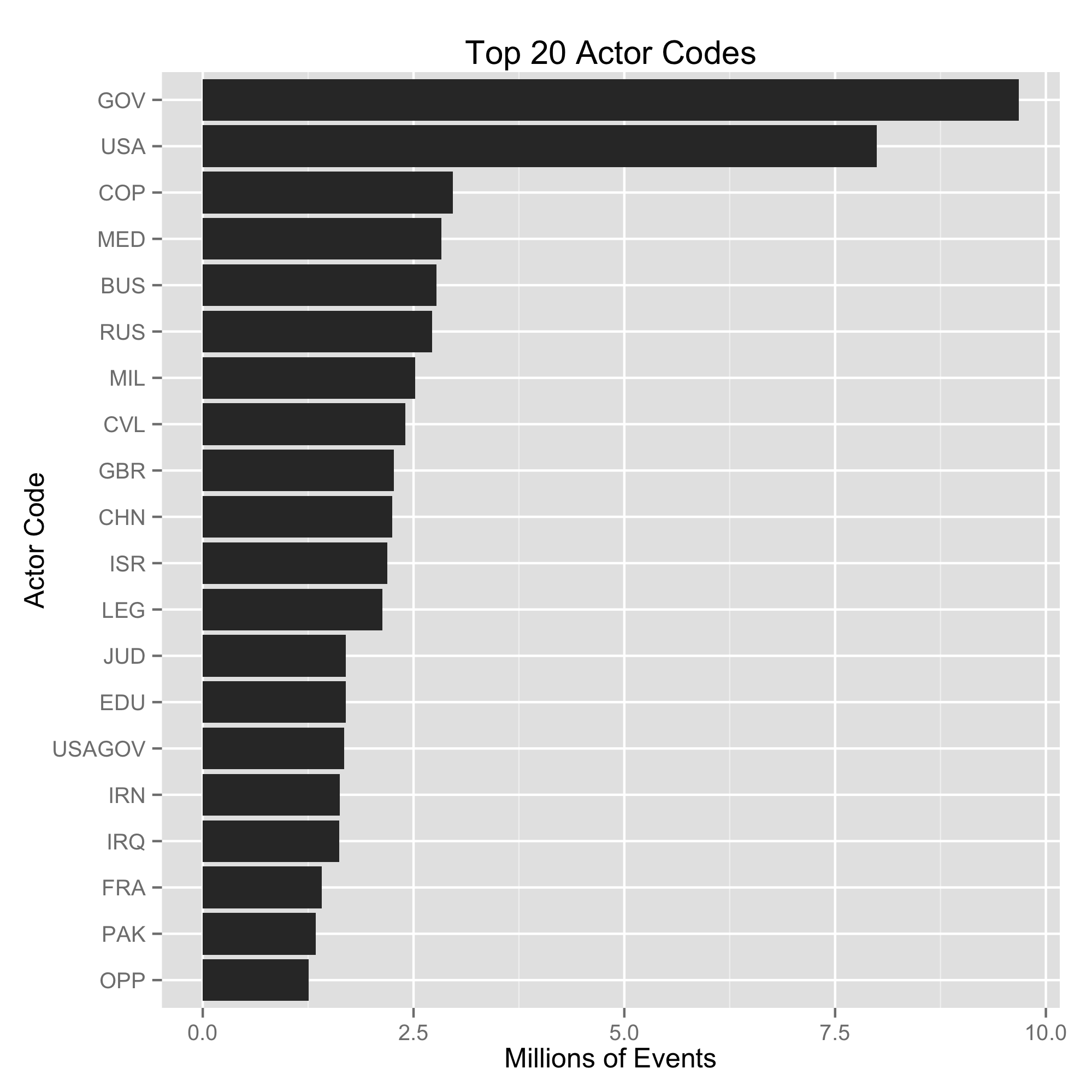
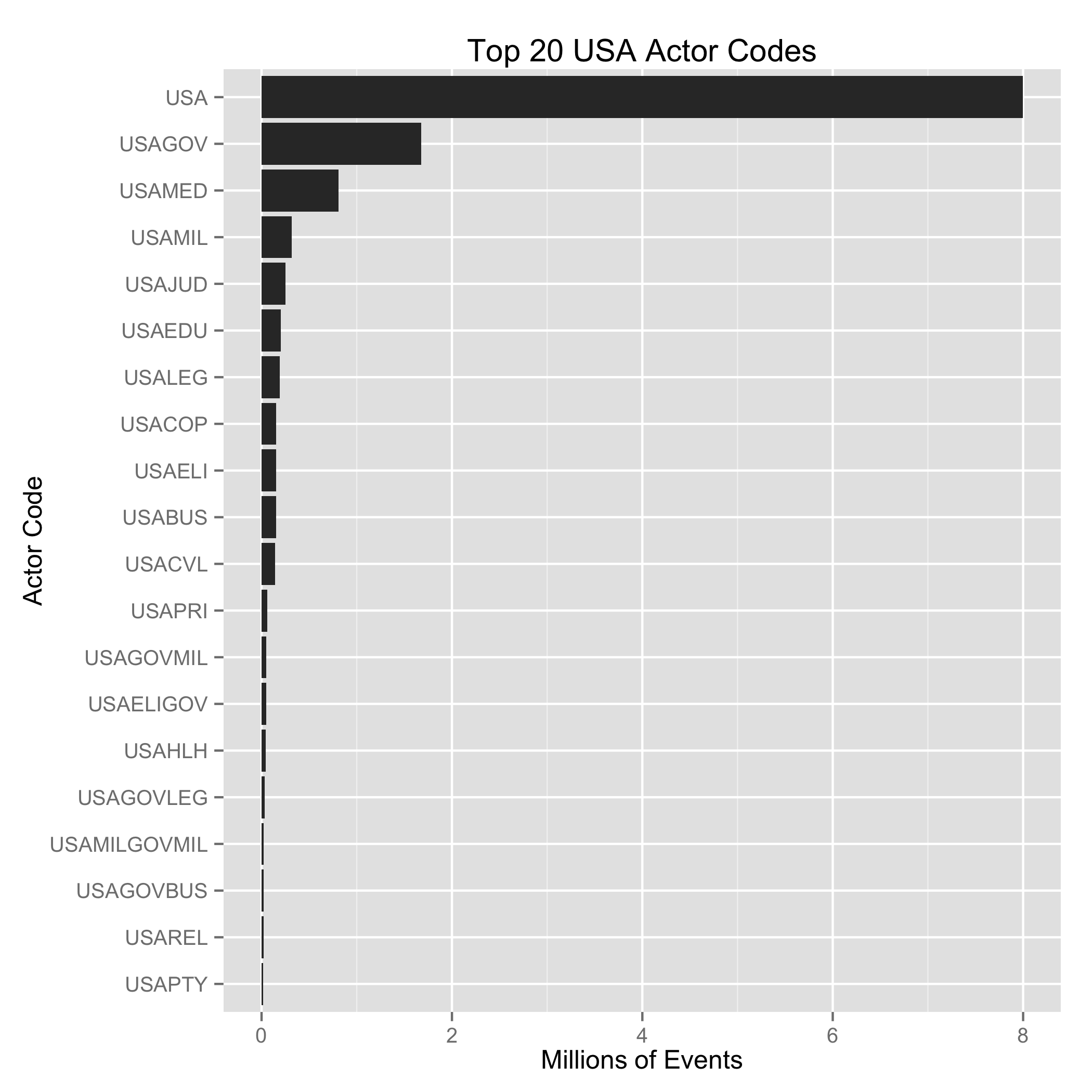
This analysis shows the incredible complexity that is present in the actor codes, which I would argue is the most important, fascinating, and challenging part of working with event data on this scale.