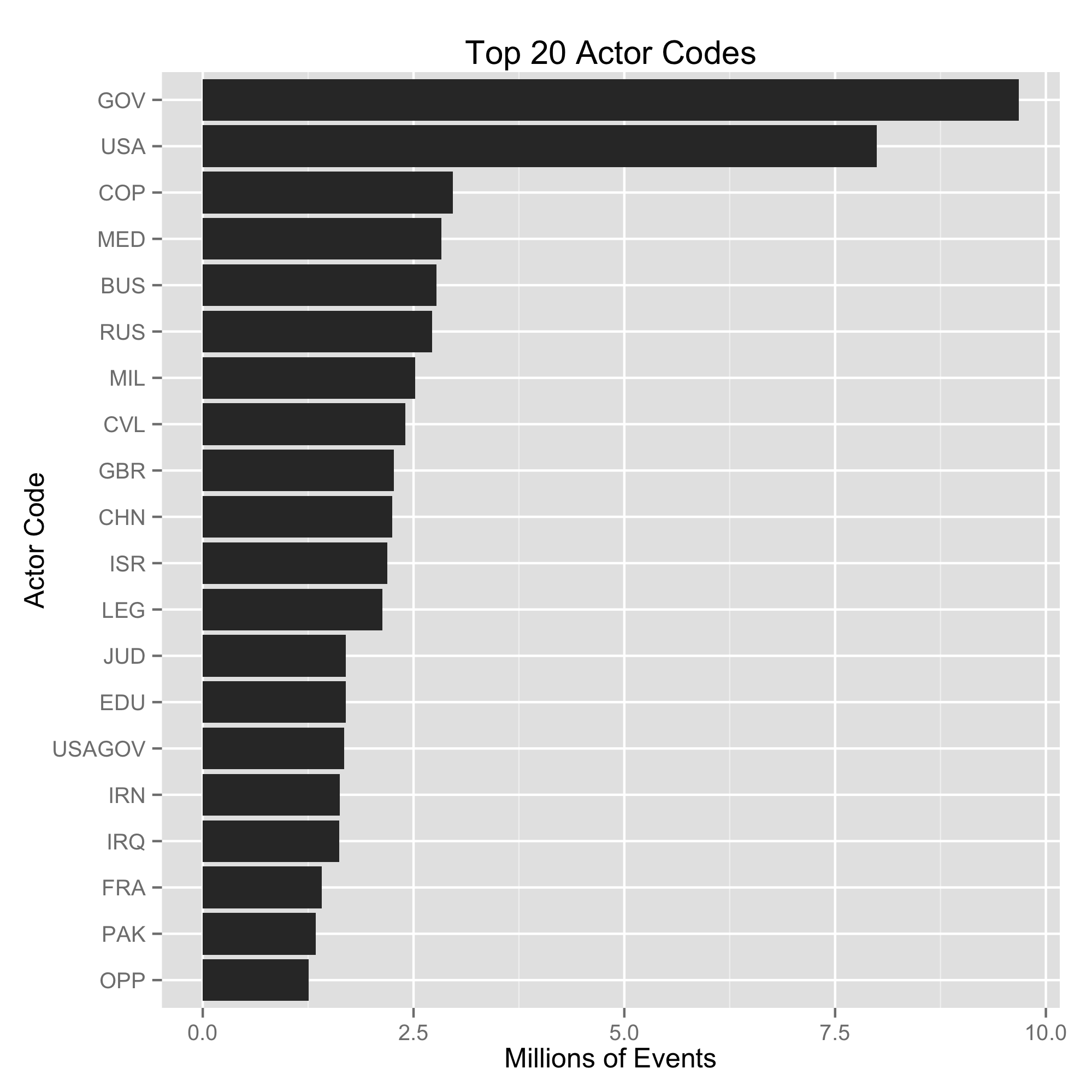
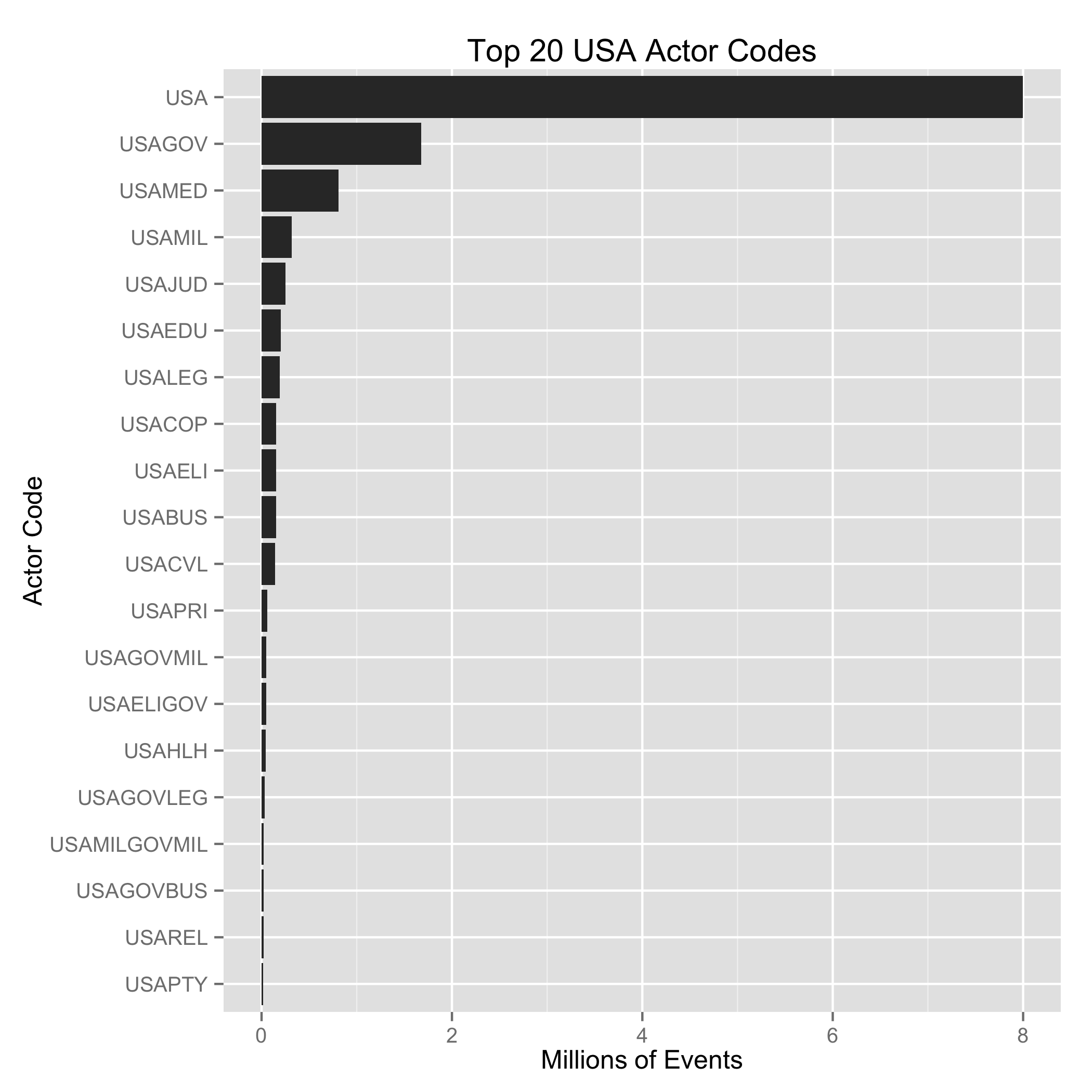
I made the remark on Twitter that it seemed like GDELT week due to a
Foreign Policy
piece about the dataset, Phil and Kalev’s paper
for the ISA 2013 meeting, and a host
of blog
posts
about the data. So, in the spirit of GDELT week, I thought I would throw my hat into
the ring. But instead of taking the approach of lauding the new age that is approaching
for political and social research due to the monstrous scale of the data now available, I thought
I would write a little about the issues that come along with dealing with such massive data.
Dealing with GDELT
As someone who has spent the better part of the past 8 months dealing with the GDELT dataset,
including writing a little about
working with the data, I feel that I have a somewhat unique perspective. The long and the
short of my experience is: working with data on this scale is hard. This may strike some
as obvious, especially given the cottage industry that has sprung up around Hadoop and
and other services for processing data. GDELT is 200+ million events spread across several
years. Each year of the reduced data is in
a separate file and contains information about many, many different actors. This is part of
what makes the data so intriguing and useful, but the data is also unlike data such as the
ever-popular MID data in
political science that is easily managed in a program like Stata or R. The data requires
subsetting, massaging, and aggregating; having so much data can, at some points, become
overwhelming. What states do I want to look at? What type of actors? What type of actions?
What about substate actors? Oh, what about the dyadic interactions? These questions and
more quickly come to the fore when dealing with data on this scale. So while the GDELT
data offers an avenue to answer some existing questions, it also brings with it many
potential problems.
Careful Research
So, that all sounds kind of depressing. We have this new, cool dataset that could
be tremendously useful, but it also presents many hurdles. What, then, should we
as social science researchers do about it? My answer is careful theorizing and
thinking about the processes under examination. This might be a “well, duh”
moment to those in the social sciences, but I think it is worth saying when
there are some heralding “The End of Theory”.
This type of large-scale data does not reduce theory and the scientific
method to irrelevance. Instead, theory is elevated to a position of
higher importance. What states do I want to look at? What type of
actions? Well, what does the theory say? As Hilary Mason noted in
a tweet:
Data tells you whether to use A or B. Science tells you what A and B should be in the first place.
Put into more social-scientific language, data tells us the relationship
between A and B, while science tells us what A and B should be and what type
of observations should be used. The data under examination in a given study
should be driven by careful consideration of the processes of interest.
This idea should not, however, be construed as a rejection of “big data” in the
social sciences. I personally believe the exact opposite; give me as many features,
measures, and observations as possible and let algorithms sort out what is important.
Instead, I think the social sciences, and science in general, is about asking
interesting questions of the data that will often require more finesse than taking an
“ANALYZE ALL THE DATA” approach. Thus, while datasets like GDELT provide new opportunities,
they are not opportunities to relax and let the data do the talking. If anything, big data
generating processes will require more work on the part of the researcher than previous
data sources.